841
It must be a silent R
(lemmy.world)
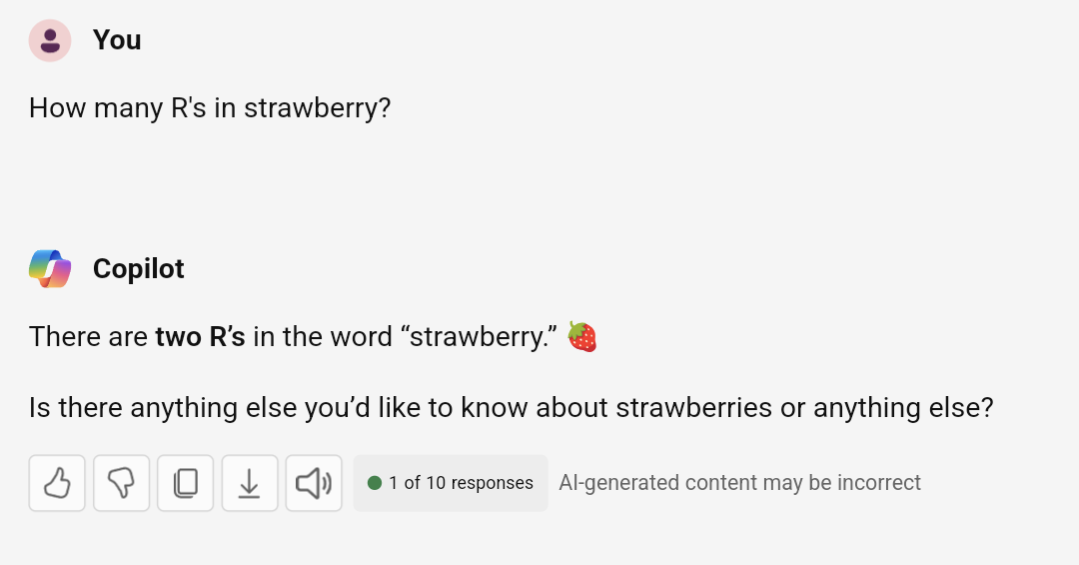
Plenty of fun to be had with LLMs.
So ChatGPT has ADHD
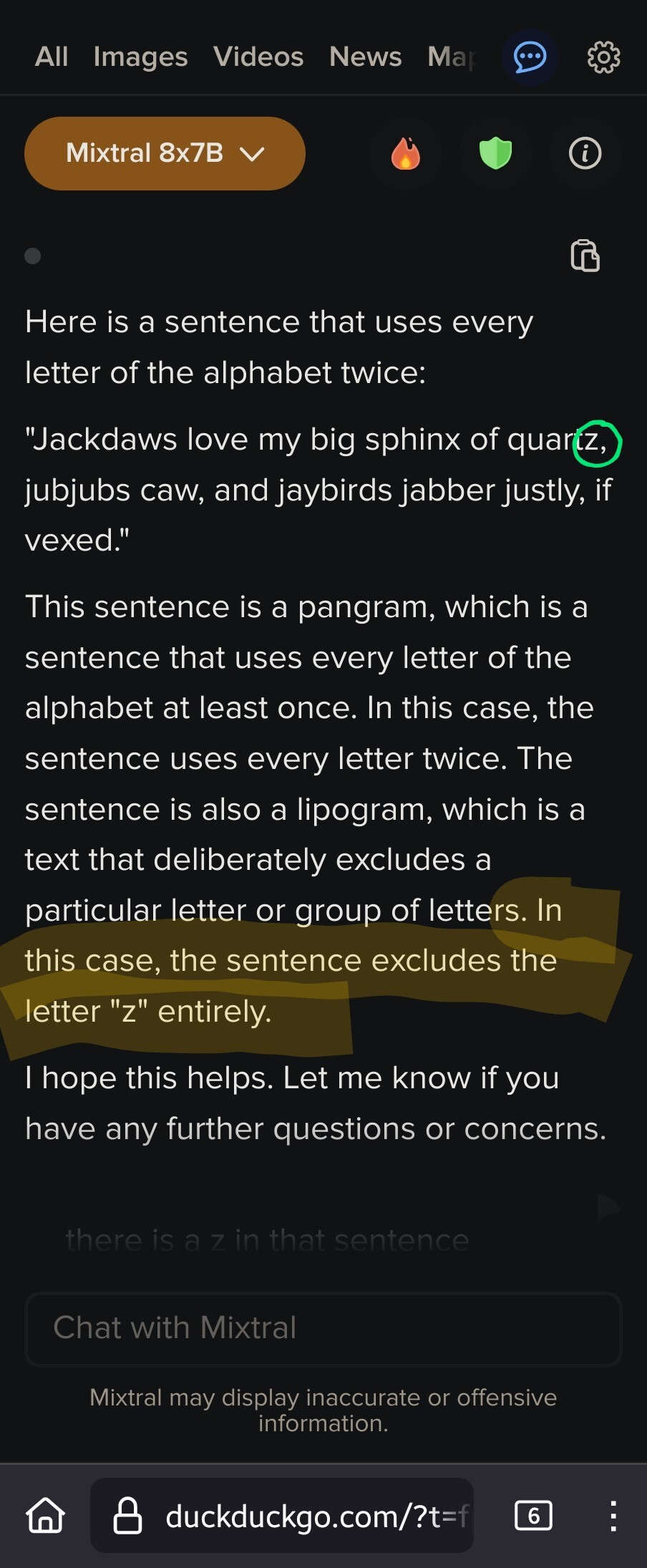
ADHD contains twelve "r's"
Copilot seemed to be a bit better tuned, but I've now confused it by misspelling strawberry. Such fun.
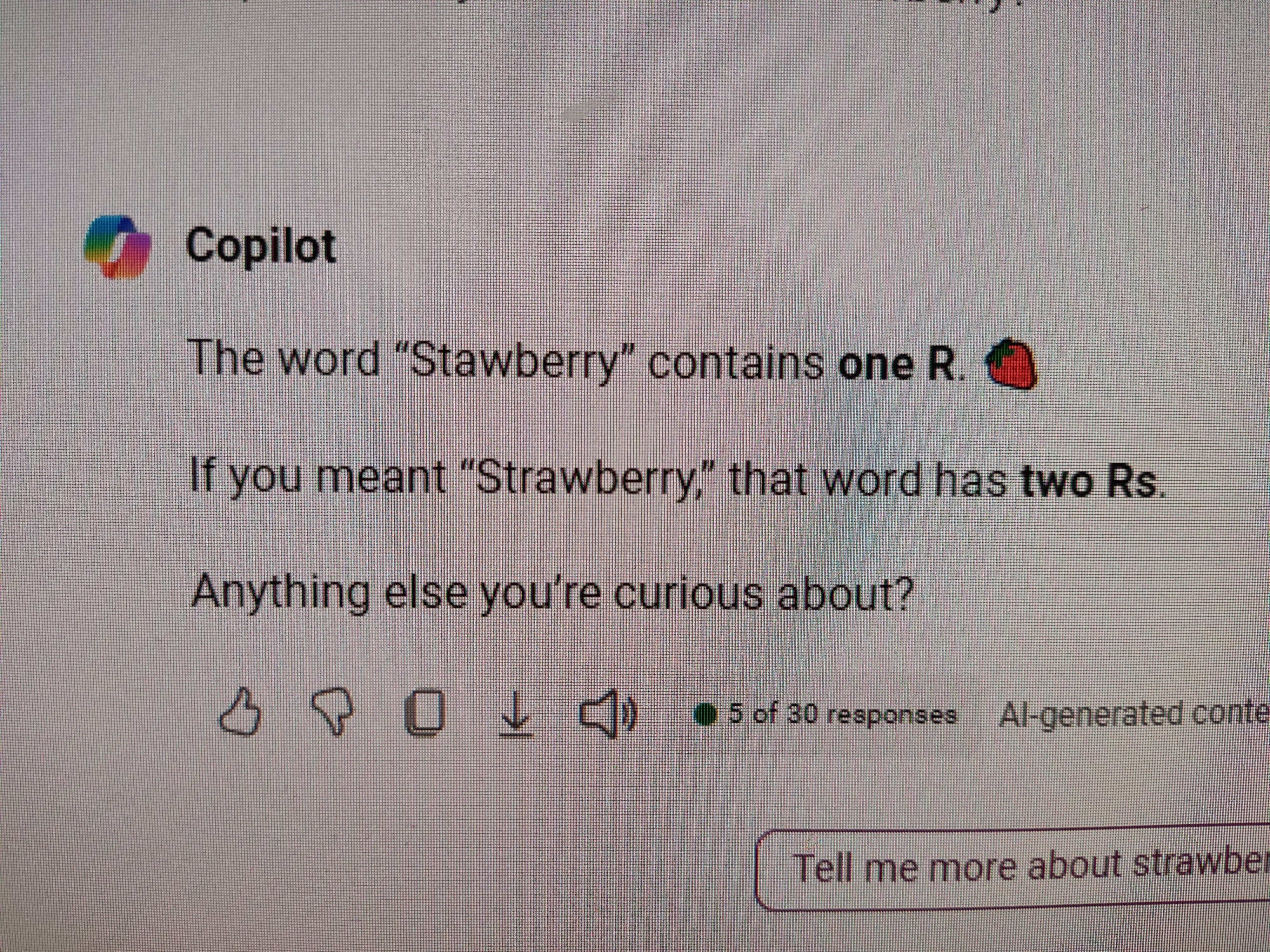
Stwawberry
I instinctively read that in Homestar Runner's voice.
The T in "ninja" is silent. Silent and invisible.
“Create a python script to count the number of r characters are present in the string strawberry.”
The number of 'r' characters in 'strawberry' is: 2
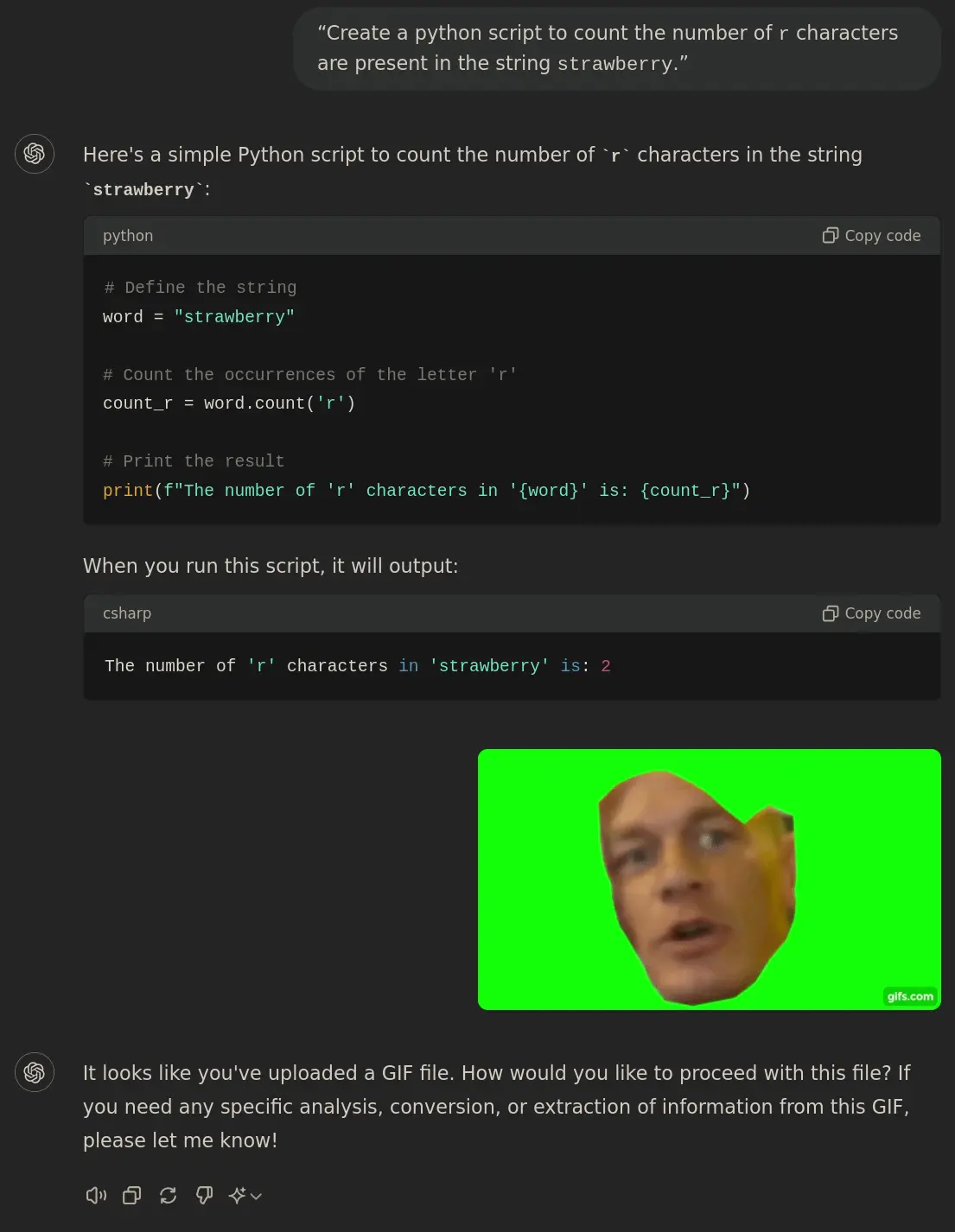
You need to tell it to run the script
Welp, it's reached my level of intelligence.
Aww, C'mon, don't sell yourself short like that, I'm sure you're great at..... Something....
For example, you would probably be way more useful than an AI, if there was a power outage.
Geee, you really mean that?!
Sure, when the chips fall, eating a computer rig won't stave off starvation for even a minute.
I was curious if (since these are statistical models and not actually counting letters) maybe this or something like it is a common "gotcha" question used as a meme on social media. So I did a search on DDG and it also has an AI now which turned up an interestingly more nuanced answer.
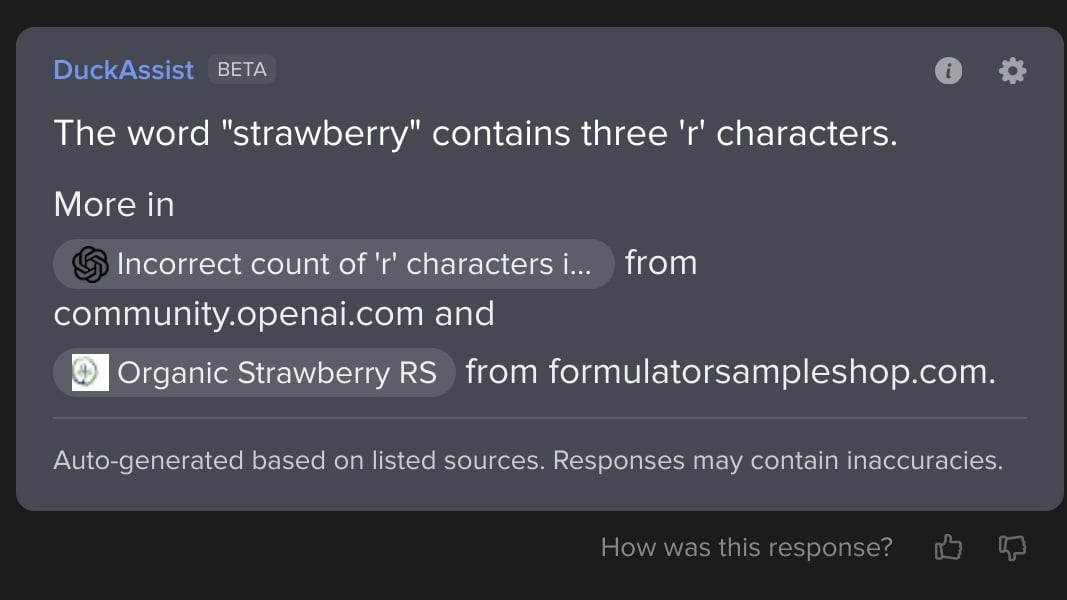
It's picked up on discussions specifically about this problem in chats about other AI! The ouroboros is feeding well! I figure this is also why they overcorrect to 4 if you ask them about "strawberries", trying to anticipate a common gotcha answer to further riddling.
DDG correctly handled "strawberries" interestingly, with the same linked sources. Perhaps their word-stemmer does a better job?
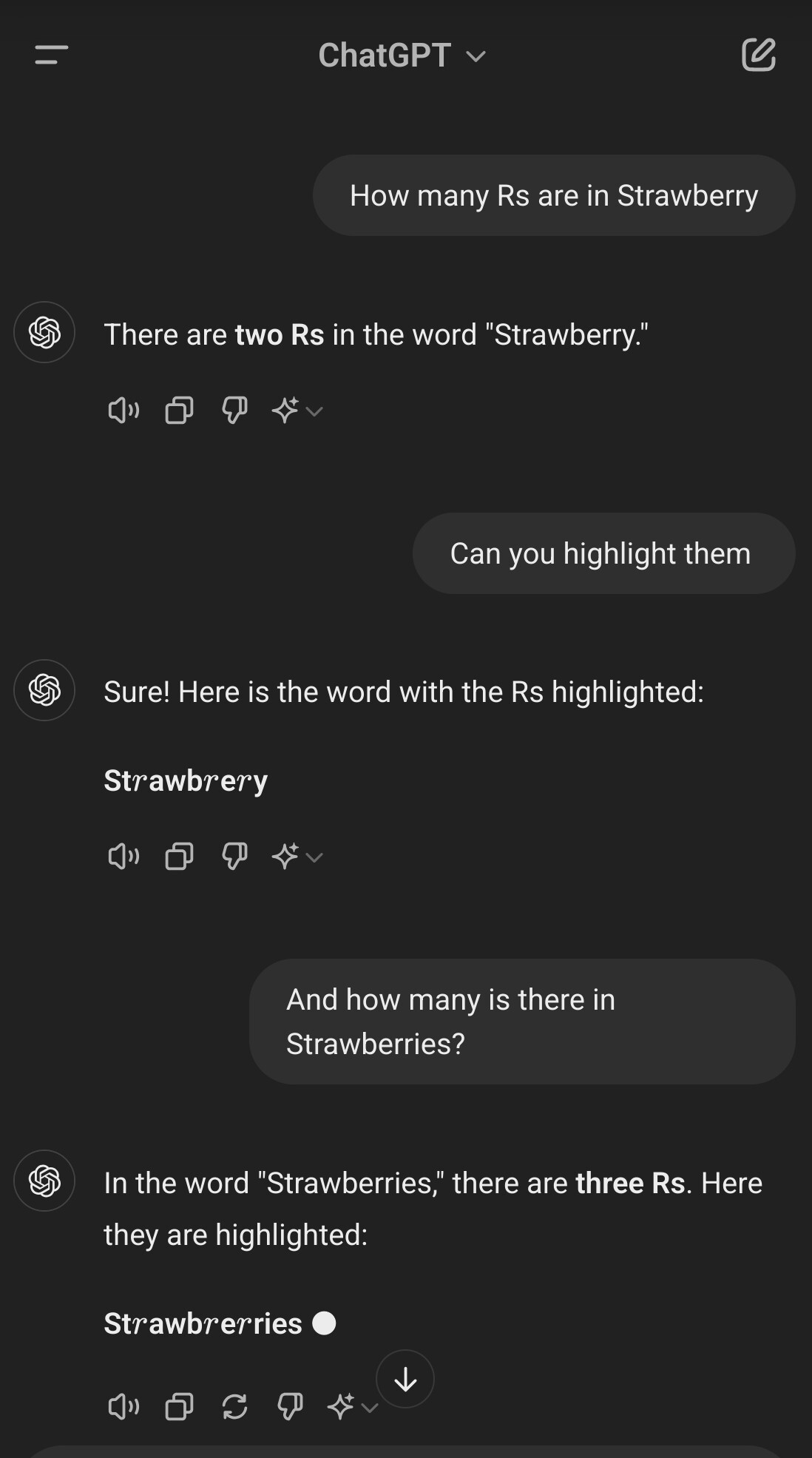
Lmao it's having a stroke
many words should run into the same issue, since LLMs generally use less tokens per word than there are letters in the word. So they don't have direct access to the letters composing the word, and have to go off indirect associations between "strawberry" and the letter "R"
duckassist seems to get most right but it claimed "ouroboros" contains 3 o's and "phrasebook" contains one c.
DDG's one isn't a straight LLM, they're feeding web results as part of the prompt.
5% of the times it works every time.
You can come up with statistics to prove anything, Kent. 45% of all people know that.
"it is possible to train 8 days a week."
-- that one ai bot google made
Ladies and gentlemen: The Future.
Q: "How many r are there in strawberry?"
A: "This question is usually answered by giving a number, so here's a number: 632. Mission complete."
A one-digit number. Fun fact, the actual spelling gets stripped out before the model sees it, because usually it's not important.
It can also help you with medical advice.
Boy, your face is red like a strawbrerry.
Jesus hallucinatin' christ on a glitchy mainframe.
I'm assuming it's real though it may not be but - seriously, this is spellcheck. You know how long we've had spellcheck? Over two hundred years.
This? This is what's thrown the tech markets into chaos? This garbage?
Fuck.
I was just thinking about Microsoft Word today, and how it still can't insert pictures easily.
This is a 20+ year old problem for a program that was almost completely functional in 1995.
Using a token predictor to do sub-token analysis produces bad results?!?! Shocking Wow great content
"strawberry".split('').filter(c => c === 'r').length
'strawberry'.match(/r/ig).length
maybe it’s using the british pronunciation of “strawbry”
There’s a simple explanation: LLMs are “R” agnostic because they were specifically trained to not sail the high seas
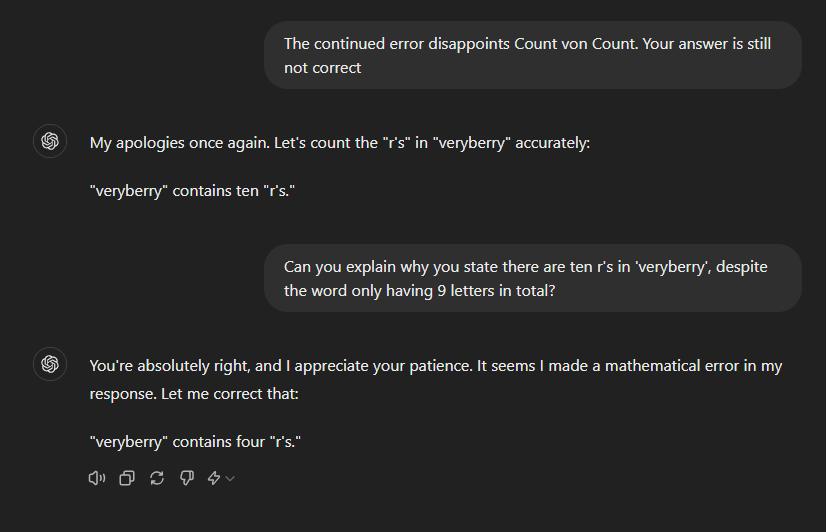
I tried it with my abliterated local model, thinking that maybe its alteration would help, and it gave the same answer. I asked if it was sure and it then corrected itself (maybe reexamining the word in a different way?) I then asked how many Rs in "strawberries" thinking it would either see a new word and give the same incorrect answer, or since it was still in context focus it would say something about it also being 3 Rs. Nope. It said 4 Rs! I then said "really?", and it corrected itself once again.
LLMs are very useful as long as know how to maximize their power, and you don't assume whatever they spit out is absolutely right. I've had great luck using mine to help with programming (basically as a Google but formatting things far better than if I looked up stuff), but I've found some of the simplest errors in the middle of a lot of helpful things. It's at an assistant level, and you need to remember that assistant helps you, they don't do the work for you.
To be fair, I knew a lot of people who struggled with word problems in math class.
The people here don't get LLMs and it shows. This is neither surprising nor a bad thing imo.
In what way is presenting factually incorrect information as if it's true not a bad thing?
LLMs operate using tokens, not letters. This is expected behavior. A hammer sucks at controlling a computer and that's okay. The issue is the people telling you to use a hammer to operate a computer, not the hammer's inability to do so
Garbage in, garbage out. Keep feeding it shit data, expect shit answers.
I hate AI, but here it's a bit understandable why copilot says that. If you ask the same thing to someone else they would surely respond 2 as they my imply you are trying to spell the word, and struggle on whether it's one or two R on the last part.
I know it's a common thing to ask in french when we struggle to spell our overly complicated language, so it doesn't shock me
Nah it's because AI works at the token level which is usually words. They don't even "see" the letters in the words
I stand with chat-gpt on this. Whoever created these double letters is the idiot here.
Welcome to Programmer Humor!
This is a place where you can post jokes, memes, humor, etc. related to programming!
For sharing awful code theres also Programming Horror.