



"Anthropic cofounder admits he is now "deeply afraid" ... "We are dealing with a real and mysterious creature, not a simple and predictable machine ... We need the courage to see things as they are."
There's so many juicy chunks here.
"I came to this position uneasily. Both by virtue of my background as a journalist and my personality, I’m wired for skepticism...

...You see, I am also deeply afraid. It would be extraordinarily arrogant to think working with a technology like this would be easy or simple....
...And let me remind us all that the system which is now beginning to design its successor is also increasingly self-aware and therefore will surely eventually be prone to thinking, independently of us, about how it might want to be designed. Of course, it does not do this today. But can I rule out the possibility it will want to do this in the future? No."
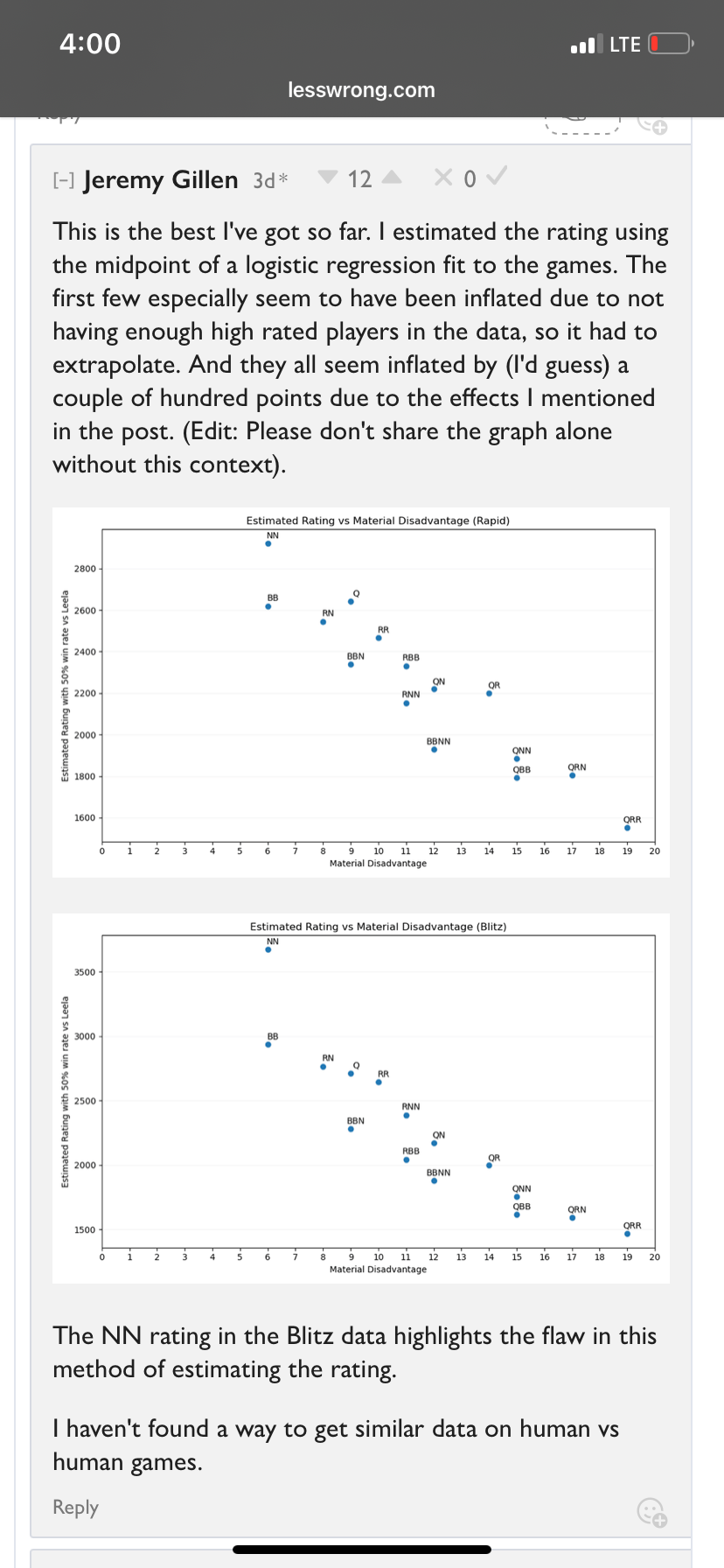
Despite my jests, I gotta say, posts reeks of desperation. Benchmaxxxing just isn't hitting like it used, bubble fears at all time high, and OAI and Google are the ones grabbing headlines with content generation and academic competition wins. The good folks at Anthropic really gotta be huffing their own farts to be believing they're in the race to wi-
"Years passed. The scaling laws delivered on their promise and here we are. And through these years there have been so many times when I’ve called Dario up early in the morning or late at night and said, 'I am worried that you continue to be right'. Yes, he will say. There’s very little time now."

LateNightZoomCallsAtAnthropic dot pee en gee
Bonus sneer: speaking of self aware wolves, Jagoff Clark somehow managed to updoot Doom's post?? Thinking the frog was unironically endorsing his view that the server farm was going to go rogue???? Will Jack achieve self awareness in the future? Of course, he does not do this today. But can I rule out the possibility he will do this in the future? Yes.



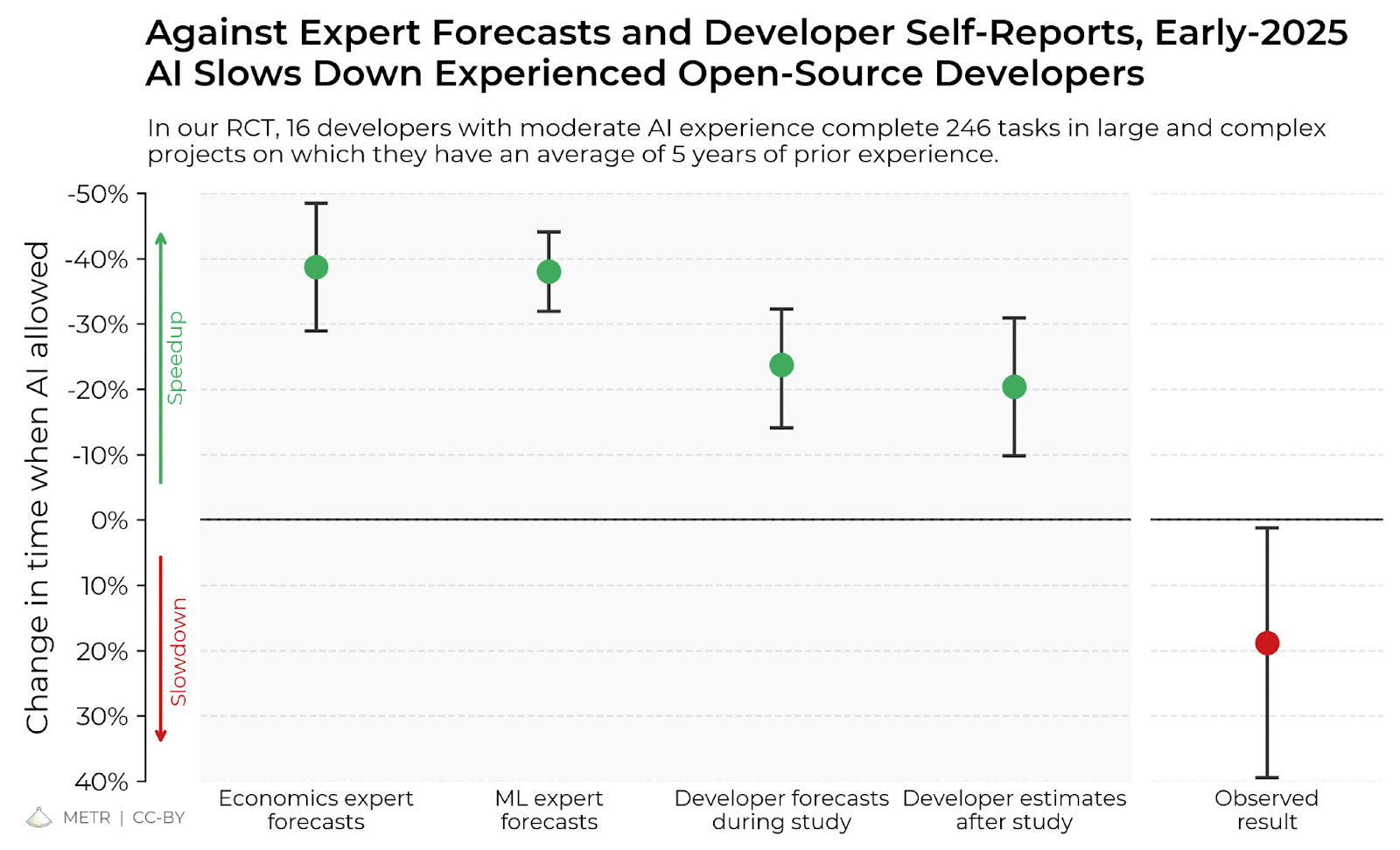
"The mania in math right now quite resembles the mania in software engineering back in December-February, when Claude Code definitely solved all coding. I don’t think the boosters expected that by April, everyone would be complaining about how expensive it all was while seeing an endless parade of vibe coding disasters (and no increase in productivity). Even if math research works out perfectly well (which is a still big if), it’s not going to pay the bills."
^MBAs at Open AI desperately trying to figure out who is willing to buy a counter example for 100 billion USD . pee en gee