2
Ylen lyhytvideouutisten puhetapa
(suppo.fi)
Damn. Who could possibly have seen this coming?
Well you'd be wrong. The law says they belong on bike paths here, and a lot of the time sidewalks are combined paths where bikes are supposed to go.
Excuse the slop but I wanted to see an illustration of what this might look like, and I can see how someone like Trump would find the second picture an improvement.


Where I'm from there's still a plenty of combined pedestrian/bike paths that have an annoyingly high curb after every crosswalk.
I don't understand how jumping curbs is supposed to be a problem, that's just something you have to do to get around sometimes. It also seems like something that hitting potholes would easily get confused for.
🚨 AI-generated alt text detected 🚨
Happens every spring. Why do you think they're called nightingales?
I'll be honest that first screenshot is not a very flattering representation of the game's graphics.
If your math uses numbers it's not real math.
§6.7.9 of the C11 standard says they have elements with indices:
If an array of unknown size is initialized, its size is determined by the largest indexed element with an explicit initializer. The array type is completed at the end of its initializer list.
The bark also peels in thin layers as it grows, which can make it harder for mosses, lichens, and other organisms to firmly establish on the surface.
Oh so that's why birch bark is the way it is.
Rosatomin perutun voimalan tilalle kaavaillaan tällaista. Otsikko sai jotenkin katsomaan kahdesti (joka luultavasti oli Ilta-Pulun pyrkimys), mutta tietenkinhän tuossa vain tarkoitetaan amerikkalaisen yhtiön (Westinghousen) rakentamaa voimalaa.
Ydinvoima on Suomessa toiminut tosi hyvin. Pääasiassa ydin- ja tuulivoiman ansiosta olemme nykyään 89-prosenttisesti hiilivapaita:

(0) Read the official Microsoft support guide, because otherwise you will never succeed.
Note that the UIs in the following steps may be in a language that you do not speak, but the support guide will naturally refer to the English localization. If you need the localized names of the UI elements, the guide is available in multiple languages. Unfortunately this will change the language of the entire guide, which may make it difficult to understand the steps themselves.
(1) Click on your profile circle in the top right and then click on this link.
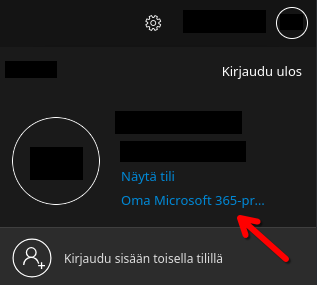
(2) On the new page that opens, click this button.
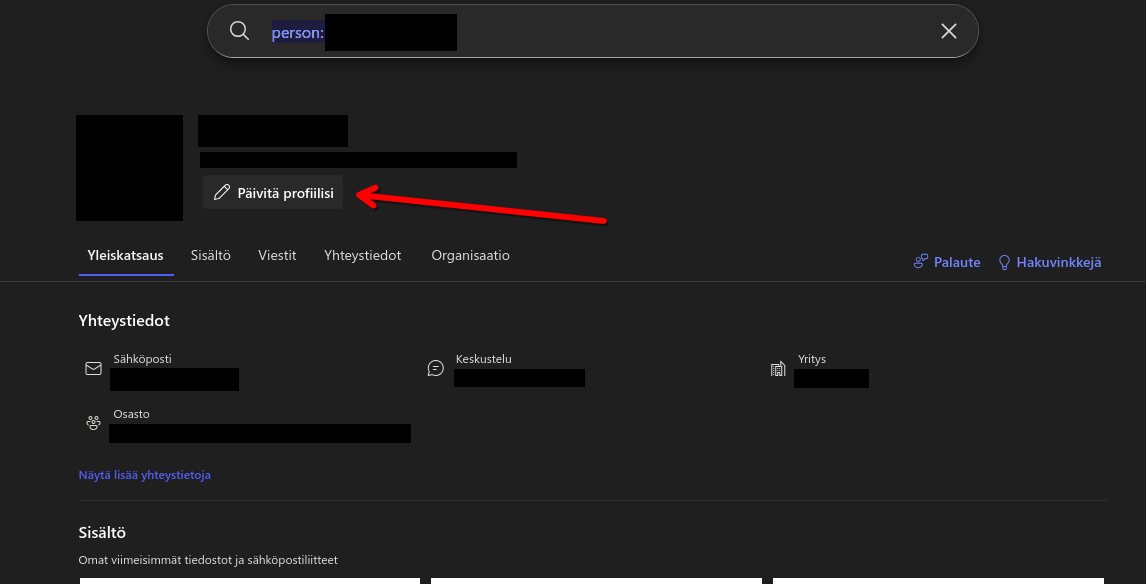
(3) In the modal pop-up, click this unassuming one-word link in the bottom left.
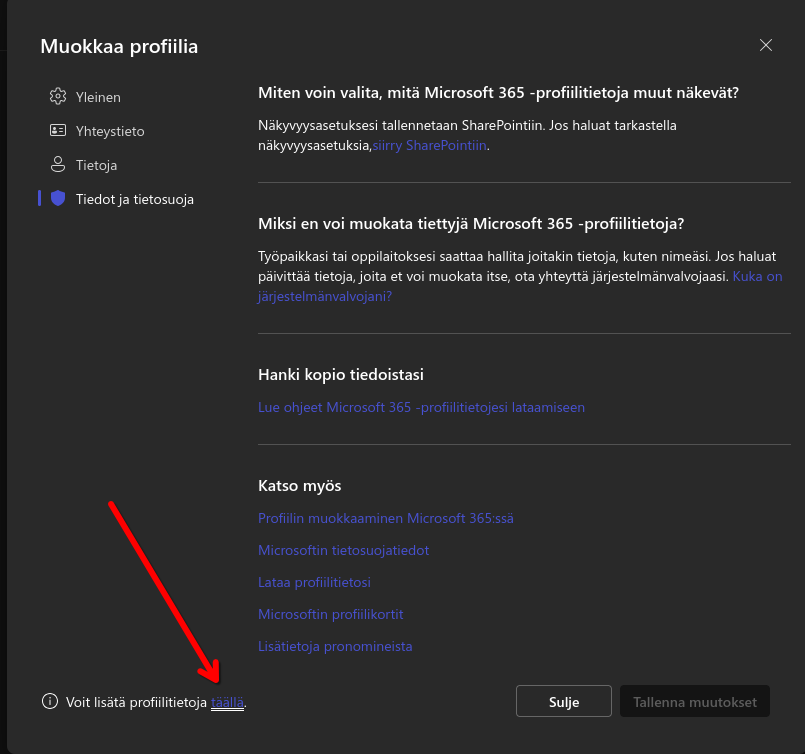
(The link translates to "You can add more profile information here.")
(4) On the new page that opens, click on the ellipsis button to show the hidden items of the horizontal navigation.
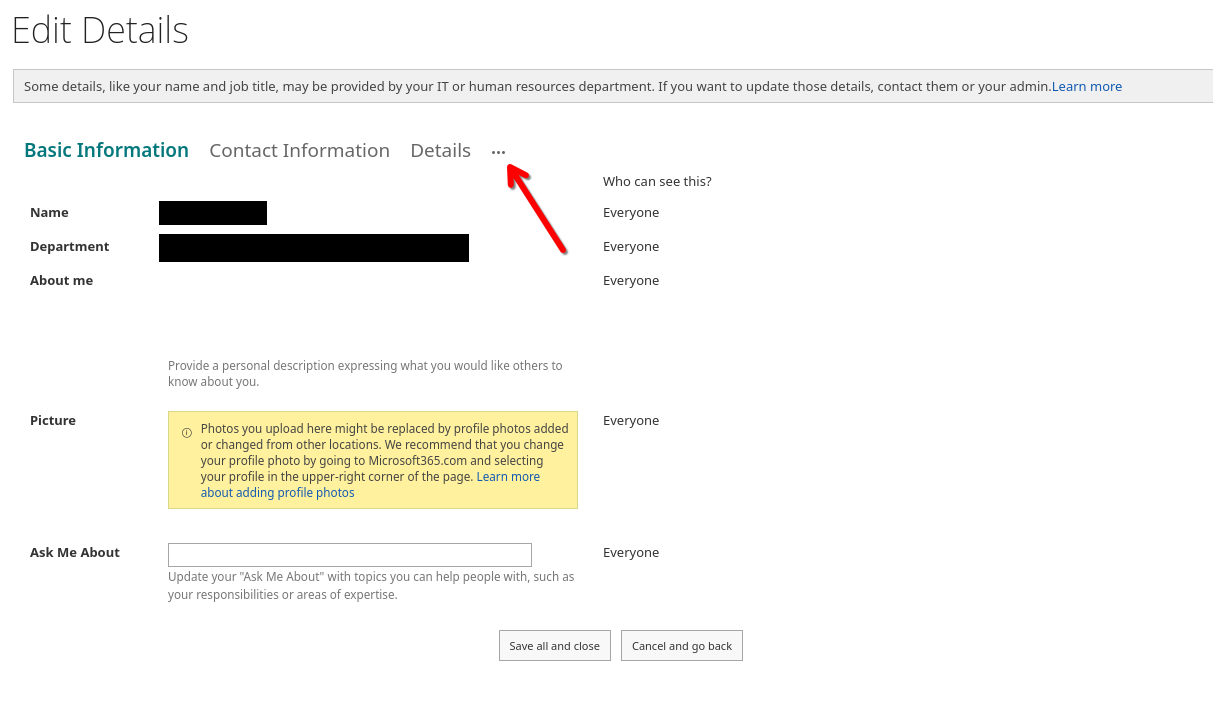
(5) Select "Language and region".
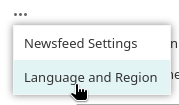
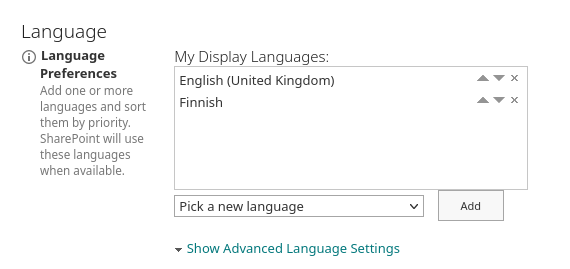
(6) Add your preferred language using the drop-down box and move it to the top of the list using the little arrows.
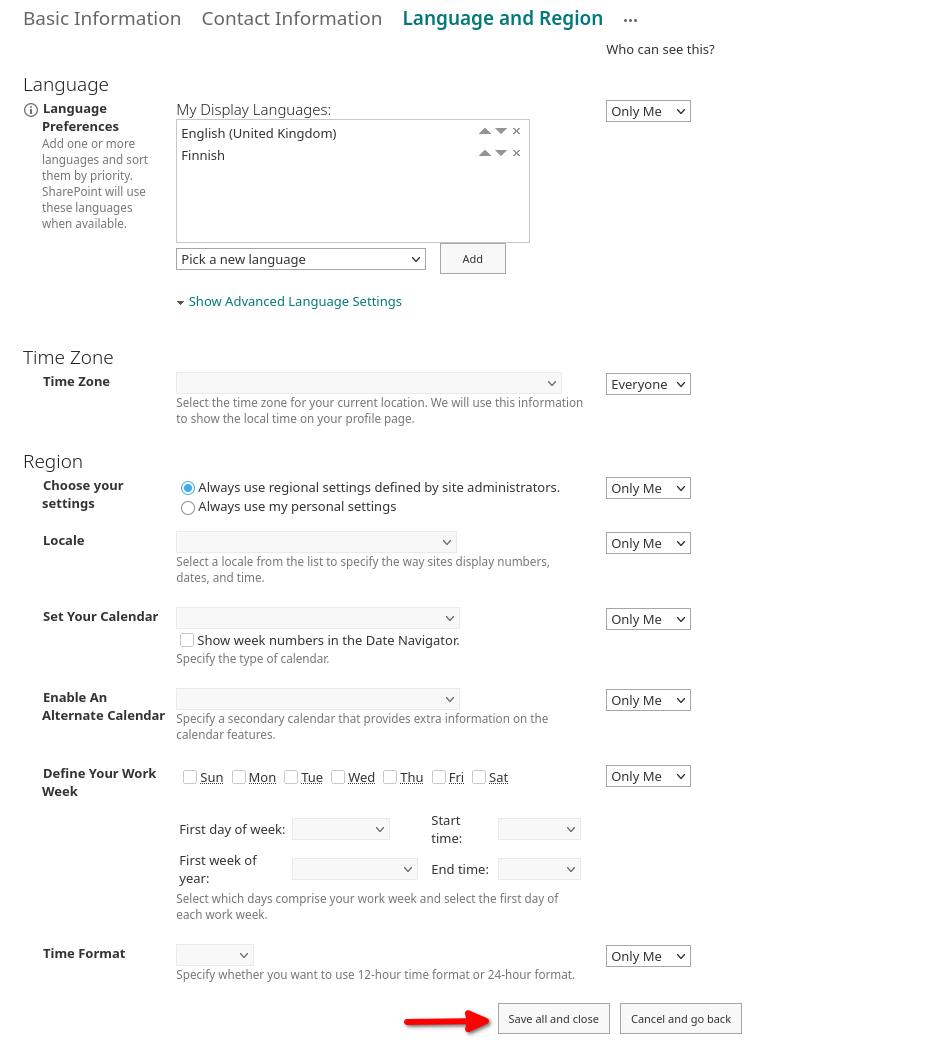
(7) IMPORTANT! Don't forget to scroll to the bottom and click on "Save all and close"!
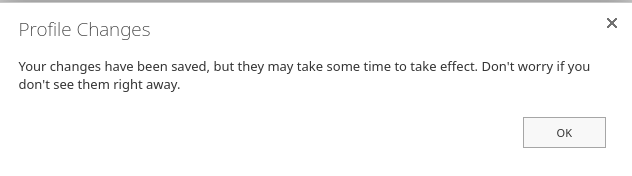
(8) Click "OK" on this pop-up.
(9) You're done and will be navigated back to the page from step 2!
Hope you didn't want to change any other settings here.
Oh, and the page from step 2 will still be in the original language. Don't worry, the pop-up dialog assured us it will change soon. Word may also still be in the original language, but should change sooner than the page from step 2 (I am still waiting on that one).
Onko vika vaan minun päässä, kun aika monessa uutispostauksessa esim. suomi@sopuli.xyz:ssa ei näy uutisen otsikkoa? Jos avaa Sopulin kautta osoitteesta https://sopuli.xyz/c/suomi niin niissä näkyy. Kuva alla.
Finland, but it's the same in all of the EU. Scooters are legally the same as bikes.