189
Chinese firms ‘distilling’ US AI models to create rival products, warns OpenAI
(www.theguardian.com)
Rules:
Also feel free to check out !leopardsatemyface@lemm.ee (also active).
Icon credit C. Brück on Wikimedia Commons.
_portrait.jpg){kind=link}
This is a lie.
Some background:
LLMs don't output words, they output lists of word probabilities. Technically they output tokens, but "words" are a good enough analogy.
So for instance, if "My favorite color is" is the input to the LLM, the output could be 30% "blue.", 20% "red.", 10% "yellow.", and so on, for many different possible words. The actual word thats used and shown to the user is selected through a process called sampling, but that's not important now.
This spread can be quite diverse, something like: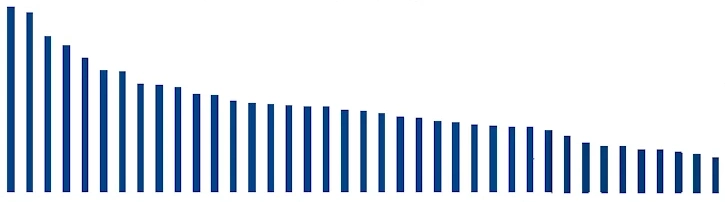
A "distillation," as the term is used in LLM land, means running tons of input data through existing LLMs, writing the logit outputs, aka the word probabilities, to disk, and then training the target LLM on that distribution instead of single words. This is extremely efficient because running LLMs is much faster than training them, and you "capture" much more of the LLM's "intelligence" with its logit ouput rather than single words. Just look at the above graph: in one training pass, you get dozens of mostly-valid inputs trained into the model instead of one. It also shrinks the size of the dataset you need, meaning it can be of higher quality.
Because OpenAI are jerks, they stopped offering logit outputs. Awhile ago.
EG, this is a blatant lie! OpenAI does not offer logprobs, so creating distillations from thier models is literally impossible.
OpenAI contributes basically zero research to the open LLM space, so there's very little to copy as well. Some do train on the basic output of openai models, but this only gets you so far.
There are a lot of implications. But basically a bunch of open models from different teams are stronger than a single closed one because they can all theoretically be "distilled" into each other. Hence Deepseek actually built on top of the work of Qwen 2.5 (from Alibaba, not them) to produce the smaller Deepseek R1 models, and this is far from the first effective distillation. Arcee 14B used distilled logits from Mistral, Meta (Llama) and I think Qwen to produce a state-of-the-art 14B model very recently. It didn't make headlines, but was almost as eyebrow raising to me.
Wait, so OpenAI's whole kerfuffle here is based on nothing directly stated (e.g. in the paper like I thought), and worse, almost certainly completely unfounded?
Wow just when I thought they couldn't get more ridiculous...
Almost all of OpenAI's statements are unfounded. Just watch how the research community reacts whenever Altman opens his mouth.
TSMC allegedly calling him a "podcast bro" is the most accurate descriptor I've seen: https://www.nytimes.com/2024/09/25/business/openai-plan-electricity.html